Confidence Intervals
An interval is a set of (real) numbers between two values. So, for example, (0, 1) is all of the real numbers x such that 0 < x < 1 .
If we have an unknown parameter, we may find an estimator for this parameter and use for the parameter. However, how reliable this estimate is we do not know. This is where confidence intervals come in. Instead of estimating the parameter, we say that there is a 95% (or some other percentage) chance that a given interval contains the parameter.
For example, suppose we have an unknown parameter q. If the probability that the interval (a,b) contains q is 0.95, i.e. if P(a < q < b) = 0.95, then (a,b) is known as the 95% confidence interval for q.
N.B. q is fixed and it is the interval which varies. It is therefore incorrect to say that there is a 95% chance that q lies in the interval. Rather, there is a 95% chance the interval contains q (a subtle, but important difference!).
Constructing Confidence Intervals
If the random variable X has a normal distribution with mean m and variance s2, then the sample mean
Image
also has a normal distribution with mean m, but with variance s2/n (see random samples). In other words,
Image
~ N(m,s2/n) .
In fact, if we have a random variable X which has any distribution (not necessarily normal), by the central limit theorem the distribution of
Image
will be approximately normal with mean m and with variance s2/n, for large n.
So standardising this, we get:
Image
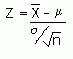
(since the mean is m and the standard deviation is s / √ n).
From the Normal Distribution section, we know that P(-1.96 < Z < 1.96) = 0.95.
Image
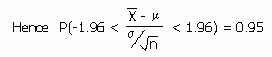
Rearranging this we get P[
Image
- 1.96(s / ? n) < m <
Image
+ 1.96(s / ?n) ] = 0.95
Hence the 95% confidence interval for m is:
(
Image
- 1.96(s / ?n) ,
Image
+ 1.96(s / ?n) )
N.B. in the confidence interval we use x not X.
Category
