Files
After studying this section you should be able to
- describe the different types of file
- design record structures
- give appropriate storage devices for the different types of file
File structure and types
A file is composed of a number of records and a record is composed of a number of fields. A field is one data item, for example a name or a price. A record consists of all the fields about one person or one item, for example an employee record (see below) or a stock item record.
Image
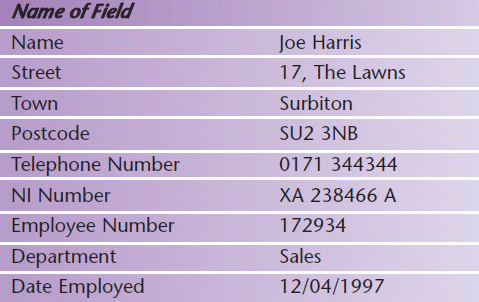
It is usually necessary to be able to identify a particular record, so one or more fields are selected as the record key (sometimes known as the key field). The important feature of this record key is that it must be unique, i.e. there must be no other records on the file with the same key. In a personnel record the record key would be the Employee Number as there will not be two employees with the same number.
A record key must be unique so don’t be tempted to suggest someone’s name, as it is quite possible for two people to have the same name.
On a disk, each file will have an entry in the directory. The directory will consist of the file’s name and various other data items associated with it, for example the date and time the file was created. One item that may be stored is the file type that can indicate what type of data is stored. Another way of identifying the file type is by giving the filename an extension. Typical file types are:
- Binary – programs or binary data, .BIN
- Text – to store text, for example, .TXT
- Graphic – to store pictures, for example, .JPG, .GIF, .TIF, .BMP
- Sound – digitised sound, .WAV, .MP3
- Video – digitised video, .AVI
- Hypermedia – web pages, .HTML
- Applications may use their own extensions, for example Microsoft Word uses .DOC.
Record types
Records can be fixed in size if all the records contain the same number of fields and all the fields are of a fixed size. Making a field a fixed size is often inconvenient as the length of names, addresses, descriptions and so on can be very variable. In this case variable length fields are required, leading to variable length records.
A more difficult problem is the situation where a variable number of fields is required. Consider the problem of storing a bank account. The customer will have some fixed fields, for example name, address, bank account number, but there will also be a variable number of transactions (deposits and/or withdrawals). This problem can be solved using a record that has a variable number of fields. A common solution is to use two record types: a record with all the fixed data and possibly a count of the number of associated transactions, followed by a variable number of transaction records.
Image
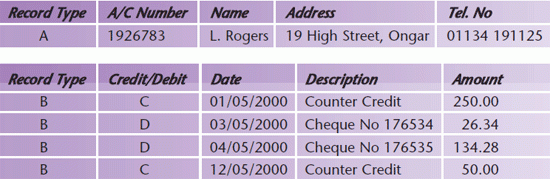
KEY POINT - Variable length records can save space, but they are more difficult to process and make it more difficult to assess the size of a file in advance.
Serial file
A serial file contains data that are in no particular order. The records are stored in the order they are received and the file is always processed as a complete file. This type of file can be stored on tape or disk. A typical use for this type of file is a transaction file where the records are in the order in which they happen to have been entered into the system.
Sequential file
A sequential file is processed serially, i.e. it is not possible to jump straight to a particular record, but the records are stored in record key order. This type of file can be stored on tape or disk. Often the transactions will need to be sorted before they can be processed. In this case the sorted transactions will become a sequential file.
Indexed sequential file
An indexed sequential file cannot be stored on a tape. This type of file is in two parts: a sequential file and an index. The index contains the record keys and the disk addresses of the records in the sequential file. This allows direct access to any record without reading the rest of the file. An indexed sequential file will be the normal file type to suggest when a file needs to be direct access and also needs to be updated regularly.
Random file
A random file may also be called a hash file or a direct access file. It cannot be stored on tape. The file consists of a number of records that are numbered. The data are stored as follows. An algorithm is applied to the record key and this produces a record number. If there is space then the record is stored in this position. If there is not space then the record is placed in an overflow position. The overflow position is calculated using another algorithm. The simplest overflow algorithm is to try the following positions until a free space is found.
A random file is faster to access than an indexed sequential file. It is very effective as a lookup file (that is, a file that is not going to be updated). It is not so useful when the file is to be regularly updated as it can easily become disorganised.
KEY POINT - Indexed sequential files and random files can only be stored on disk, whereas serial files and sequential files can be stored on both disk and tape.
Category
